
优酷土豆hadoop 平台开放之路(2)
引入Kerberos
Hadoop 在1.0 以后的版本中支持了Kerberos,我们将Kerberos 安全认证开启,上述描述的相关问题都能得到解决。下图所示为Kerberos 的主体结构图,包括Identity Store 和KDC 两部分。其中Identity Store 主要包含身份认证信息,KDC 为密钥分发服务器。引入Kerberos 后,新增用户、新增节点需要在Kerberos 上分配相应的身份信息。我们通过自动化脚本可以一键解决。
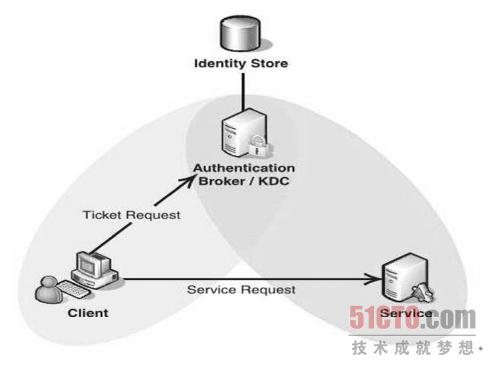
用户请求服务的时候需要先从KDC 分发Ticket,这样KDC 存在一个单点故障问题。引入一个新的系统,多了一个环节必然会带来一些新的问题。我们配置了主从KDC 服务,同时利用脚本实时同步主从库的认证信息,这样大大增强了Kerberos 的可靠性。
用户组信息控制
HDFS 文件系统设计模拟了Linux 文件系统,所以HDFS 文件属性的设计也遵从Linux 文件。每个文件拥有读、写、执行三种操作,每个文件只能归属于一个所有者,归属于一个组,每个文件都定义了所有者和组用户的权限。这样三种不同的身份对三个不同的操作进行排列组合,即一共拥有9 种不同的配置策略。这样的设计比较简单,但是其权限分配却不够灵活。
我们发现,Hadoop 若要对文件实现灵活的权限控制需要设置组用户的权限。而Hadoop 本身并没有存储用户的权限信息,而是在进行用户权限判断的时候通过调用一个接口来获取Linux 客户端的用户组信息,也就是说,如果客户端用户的组信息与HDFS 上的权限信息不匹配,那么程序就会报错。
此外,如果组信息依赖于客户端机器的话也很容易使用户的组信息被造假。此外,连接到数据平台的客户端机器数量较多,如果需要在多个客户机上维护一些相同的用户组信息,那么会导致用户组信息的数据不一致。
若想对某个用户的组信息进行更改,需要先知道哪几台客户端机器拥有这个用户的登录信息,然后分别需要在这些机器上将客户端的组信息全部更改。这样在操作管理上极为不方便,有时候一些用户的权限信息更改比较频繁而且又比较迫切,这样就会为难管理员。
综上分析,我们发现Hadoop 默认Linux 客户端的组信息存在以下几个不足之处:
1.任何客户端的不安全都会破坏集群的安全。
2.客户端机器众多,映射关系数据的一致性比较困难。
3.复杂的权限资源配置需求无法得到满足。
4.管理极其不方便。
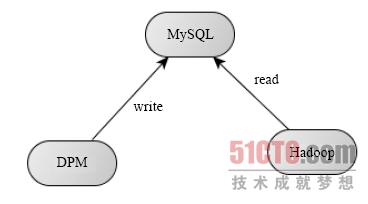
鉴于上面分析的结果,我们将Hadoop 读取用户组信息的接口进行重写,将信息持久化到一个独立的关系数据库中。如下图所示,将hadoop.security.group.mapping 配置为自己实现的一个类,使得Hadoop是通过MySQL 数据库获取用户的组信息,这样所有用户的组信息都集中在一个地方进行管理。另外,我们开发了一个DPM 工具,用于修改MySQL 中的用户组信息,这样如果用户需要访问一个新的资源,管理员只需要通过DPM 工具就可以轻松授权。
Web UI 访问控制
Hadoop 默认提供两个Web 界面(50030 和50070)用来供用户查询信息。默认这两个界面并未对用户身份进行认证,任何用户都可以访问HDFS 上的数据,这对一些私有数据的安全性是没有保证的。此外,用户可以看到所有作业运行信息以及相关配置信息,有时我们会将一些数据库配置的账号密码加载到配置文件中,这样通过Web 界面暴露出来,会带来一些其他安全问题。
针对这个问题,我们修改了Hadoop 默认的Serverlet 过滤器,用户第一次访问Web UI 界面会自动跳转到一个登录界面,要求用户输入用户名和密码,该用户名和密码在注册时由用户自行设定,管理员进行审核。用户登录认证通过则会生成一个访问 token 并存储到cookie 中,下次访问时无须登录。此外,用户的token 与用户的身份也是绑定的,用户只能访问其有权限的数据,这样就可以实现对Web UI 的访问控制。
安全架构图
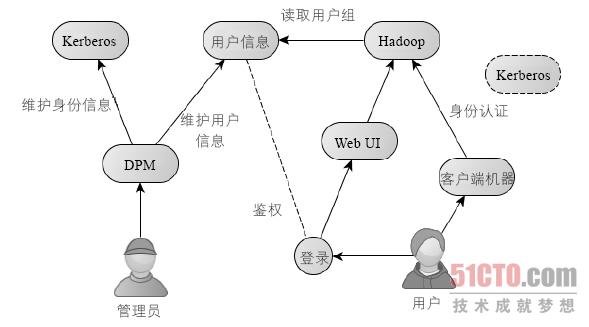
下图所示为整体安全架构图,其中管理员通过DPM 工具可以操作Kerberos、用户信息、Linux 客户端,其中用户信息存储在MySQL 数据库中。Hadoop 通过MySQL 数据库中的用户组信息对用户的请求进行权限判断,管理员修改用户信息5 分钟后就可以生效到Hadoop 系统中。DPM 还提供用户注册、管理员审核、报警等功能。
平台运营
解决了安全问题只能说Hadoop 平台开放出去了,完成这个阶段只是起步,代表平台处于一个可用的状态。当然我们期望的结果不仅仅是能开放而是要开放好。如何才能运营好一个Hadoop 平台,技术往往占很少的一部分,还需要从很多方面进行规范和监控。
规范
每个用户的使用习惯不一样,每个用户的操作水平不一样,如果没有统一的规范会使平台不好用,会增加用户之间的沟通成本,会提高管理员的维护成本。 Hadoop 主要提供了两个服务:存储与计算,我们需要制定存储规范和计算规范。HDFS 是一个文件系统,从根目录开始制定每一级的目录以及相应的业务含义,从用户角度来看,我们在根目录创建了一个user 和work 目录,其中user 为用户的私人空间,设置一定配额,供用户存储个人数据;work 目录为团队目录,配额比较大,用于存储团队业务信息,线上的业务信息不允许放置在user 下。当然还有其他目录,如:/tmp、/common、/tmp、/warehouse 等,具体要根据每个公司的业务而定。当然我们还设置了命名规范,所有的目录都用小写字母命名等。规范保证了随着时间的推移,平台依旧像刚部署时一样。规范的制定不求一次到位,可以在实践中不断完善。
流程
用户注册新账户需要流程,这样会促使用户先熟悉平台规范,同时在一进入平台就养成良好的习惯。用户申请权限需要流程,保证数据访问的安全。平台发布新特性需要走升级流程。流程减少了管理人员与用户的不必要沟通。流程的制定需要把握合适的度,不能多余烦琐,把握住关键的点就好。流程一旦推行,一定要坚持,这样才能保证后续新流程的顺利执行。流程实施的情况在某种程度上可以反映平台的运营情况。
监控
所谓监控就是在事故发生前发现前兆,采取措施避免造成损失,或者将损失最小化。监控实际上也是对现有服务的分析,可以通过监控的结果指导集群参数调优。
节点健康监控
编写脚本监控各节点是否存活,以及相应的报警措施,以免大批量的节点宕机未及时发现,造成损失。特别是SecondNameNode 存活状况的检查。
磁盘使用监控
需要监控每个节点的每个磁盘的具体使用情况,并对磁盘使用做配额限制,及时报警。
异常分析
对NameNode、DataNode 的日志中的异常定期进行分析,分析到最后几乎没有不熟悉的异常信息。
用户存储配额监控
对用户的HDFS 配额进行监控,提醒用户及时清理过期数据。
队列监控
监控队列的实时调度信息,每个作业的等待信息,以及Mapslot 和ReduceSlot 的消耗比,以此来调整队列的参数,以及MapSlot 与ReduceSlot 数。
历史作业分析
分析历史作业运行情况,核算每个团队消耗的计算资源,根据历史作业对集群参数进行调整。
总结
平台开放至今大大小小的问题也遇到不少,每一次问题的出现都会促使我们思考是否需要修改流程、是否需要添加规范、需要要新增监控点。从最初的1 个团队在使用平台,目前全集团已经有20 多个团队在使用,超过100 多个注册用户,每天提交作业数超过7000,平台运营至今一共运行的作业数超过200 万。目前平台运营比较稳定,每周只需投入1 个人日进行日常维护即可。


