
优酷土豆hadoop 平台开放之路(1)
傅杰
背景
早在2011 年之前,只有优酷网数据团队在使用Hadoop。两年间随着Hadoop 技术的推广以及大数据的影响,越来越多的领域都在使用Hadoop,公司的其他团队也在逐步引入Hadoop 技术。2012 年3 月12日,优酷土豆宣布合并,这个新闻足以让业界沸腾。随之而来的需要我们对两个视频网站的数据进行整合、业务进行整合。在整合之前,两边各自拥有一个比较大的Hadoop 集群。为了更好地支撑业务合并,以及对其他团队大数据存储与技术的支持,我们需要将两个Hadoop 集群合二为一,构建一个开放且安全的Hadoop 统一平台。
搭建开放平台
所谓开放,就是能够开放给公司任何有需要数据平台的其他职能团队,这其中包括技术团队与非技术团队。开放即共享 Hadoop 集群:HDFS 上存有各种数据,有公用的,有机密的,不同的用户可以访问不同的数据。这意味着平台用户随时可能进行一些破坏平台的动作(包含恶意及非恶意)。所以我们首先要保证平台的安全性及健壮性。
拓扑架构
大家在初接触Hadoop 时,不管是学习还是生产应用,不可避免地需要搭建Hadoop。下图为一个比较安全的Hadoop 集群的拓扑结构图。
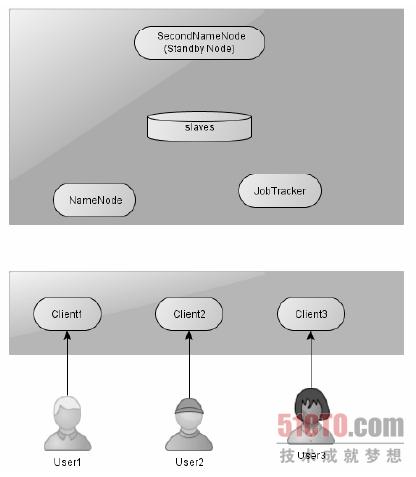
NameNode 与JobTracker 分开部署,SecondNameNode 也独立于NameNode 部署,此外,SecondNameNode 还充当了备用机的角色,当JobTracker 或者NameNode 出现故障时可以快速恢复服务。用户对集群的操作只能通过平台提供的客户端机器来执行,用户不能直接访问集群中的任何一个节点,这样在运营管理上我们只需要关注几个关键的节点。此外,随着开放的用户越来越多,为了方便后续的扩展,我们将分配多个客户端机器,将不同的团队分配到不同的客户端机器上,同时也起到备用的作用。
为了充分利用资源,我们按照各个团队使用的情况分配相应的客户机,这会出现某个客户机有多个团队共同使用的情况。由于每个人的习惯不同,很可能出现某个用户的操作使得整个客户端宕机。所以在构建客户端的初期就需要制定严格的规范,哪些目录供生产使用、哪些目录供测试使用以及对每个用户团队实行配合管理。当然还需要对机器资源进行监控,防止用户在客户机上提交非相关的程序。前期规范好可以减少很多后期维护成本。
安全架构
任何系统要实现开放都要先解决安全问题。我们知道大部分团队引入Hadoop 都是因为它的存储能力以及分布式计算能力,至少在早期并不会考虑太多安全问题。但是Hadoop 确实存在一些安全问题。比如身份认证问题、用户权限问题、Web 界面访问控制问题等。
Linux 终端的随意连接
Hadoop 集群默认并没对连接其服务的Linux 终端做身份认证,所以只要知道服务地址就可以访问资源。假设用户A通过另一台未知的Linux终端连接到我们的集群,并且该用户拥有这个终端的root 账户,那么该用户就可以通过这个终端操作HDFS 的所有资源,这对开放数据平台来说是极度不安全的。
非法应用的连接
一般我们会开发一些应用连接Hadoop 的HDFS 服务,比如日志采集系统将外部的业务系统采集过来的日志直接上传到HDFS 上。在之前的数据平台中并没对第三方应用做身份认证,任何APP 只要知道其服务地址就可以往HDFS 上存储数据、修改数据,这样对现有的数据是极其不安全的。同时还可以开发一些私有的应用程序用来过度消耗数据平台的计算资源,导致日常的业务计算得不到足够的计算资源从而影响正常的业务报表。
用户身份的冒充
在我们提交MapReduce 作业时,只要将user.name 的属性设置成你期望伪造的身份,就可以冒充该身份进行作业提交。这将导致其一:A用户冒充B 用户提交作业,访问本来A 用户并没有权限访问的数据,其二:在平台做成本估算报表时会将A消耗的计算资源都算到B 用户身上,这样导致估算的结果不准确。
slave 节点随意添加
Hadoop 的两个主要部分HDFS 和MapReduce 都是master/slave 结构的,所以在master 节点确定以后,slave 节点在之前的集群是可以随意添加到master 中的,这样一些不可靠的slave 添加有可能导致数据的丢失以及作业的失败。假设我们每一份文件都是三个备份存储,随后被其他用户添加几个未知的slave 节点到集群中,恰好某个文件的三个备份都存储在这新添加的slave 节点上,之后如果非法用户恶意将这些节点同时下架,那么将导致这个文件的丢失。此外,在MapReduce 框架中我们设置了某个task 尝试4 次如果不成功则将被视为失败,如果新添加的这些slave 节点环境配置以及扩展包配置与集群中的其他节点不一致,很可能导致task 的多次失败最终将导致作业的失败。


