本节介绍使用HDFS 的API 编程的简单示例。
下面的程序可以实现如下功能:在输入文件目录下的所有文件中,检索某一特定字符串所出现的行,将这些行的内容输出到本地文件系统的输出文件夹中。这一功能在分析MapReduce 作业的Reduce 输出时很有用。
这个程序假定只有第一层目录下的文件才有效,而且,假定文件都是文本文件。当然,如果输入文件夹是Reduce 结果的输出,那么一般情况下,上述条件都能满足。为了防止单个的输出文件过大,这里还加了一个文件最大行数限制,当文件行数达到最大值时,便关闭此文件, 创建另外的文件继续保存。保存的结果文件名为1,2,3,4,…,以此类推。
如上所述,这个程序可以用来分析MapReduce 的结果,所以称为ResultFilter。
程序:Result Filter
输入参数:此程序接收4 个命令行输入参数,参数含义如下:
<dfs path>:HDFS 上的路径
<local path>:本地路径
<match str>:待查找的字符串
<single file lines>:结果每个文件的行数
程序:ResultFilter
- import java.util.Scanner;
- import java.io.IOException;
- import java.io.File;
- import org.apache.hadoop.conf.Conf iguration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FSDataOutputStream;
- import org.apache.hadoop.fs.FileStatus;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- public class resultFilter
- {
- public static void main(String[] args) throws IOException {
- Conf iguration conf = new Conf iguration();
- // 以下两句中,hdfs 和local 分别对应HDFS 实例和本地文件系统实例
- FileSystem hdfs = FileSystem.get(conf);
- FileSystem local = FileSystem.getLocal(conf);
- Path inputDir, localFile;
- FileStatus[] inputFiles;
- FSDataOutputStream out = null;
- FSDataInputStream in = null;
- Scanner scan;
- String str;
- byte[] buf;
- int singleFileLines;
- int numLines, numFiles, i;
- if(args.length!=4)
- {
- // 输入参数数量不够, 提示参数格式后终止程序执行
- System.err.println("usage resultFilter <dfs path><local path>" +
- " <match str><single f ile lines>");
- return;
- }
- inputDir = new Path(args[0]);
- singleFileLines = Integer.parseInt(args[3]);
- try {
- inputFiles = hdfs.listStatus(inputDir); // 获得目录信息
- numLines = 0;
- numFiles = 1; // 输出文件从1 开始编号
- localFile = new Path(args[1]);
- if(local.exists(localFile)) // 若目标路径存在, 则删除之
- local.delete(localFile, true);
- for (i = 0; i<inputFiles.length; i++) {
- if(inputFiles[i].isDir() == true) // 忽略子目录
- continue;
- System.out.println(inputFiles[i].getPath().getName());
- in = hdfs.open(inputFiles[i].getPath());
- scan = new Scanner(in);
- while (scan.hasNext()) {
- str = scan.nextLine();
- if(str.indexOf(args[2])==-1)
- continue; // 如果该行没有match 字符串, 则忽略之
- numLines++;
- if(numLines == 1) // 如果是1, 说明需要新建文件了
- {
- localFile = new Path(args[1] + File.separator + numFiles);
- out = local.create(localFile); // 创建文件
- numFiles++;
- }
- buf = (str+"\n").getBytes();
- out.write(buf, 0, buf.length); // 将字符串写入输出流
- if(numLines == singleFileLines) // 如果已满足相应行数, 关闭文件
- {
- out.close();
- numLines = 0; // 行数变为0, 重新统计
- }
- }// end of while
- scan.close();
- in.close();
- }// end of for
- if(out != null)
- out.close();
- } // end of try
- catch (IOException e) {
- e.printStackTrace();
- }
- }// end of main
- }// end of resultFilter
程序的编译命令:
- javac *.java
运行命令
- hadoop jar resultFilter.jar resultFilter <dfs path>\
- <local path><match str><single f ile lines>
参数和含义如下:
<dfs path>:HDFS 上的路径
<local path>: 本地路径
<match str>: 待查找的字符串
<single file lines>: 结果的每个文件的行数
上述程序的逻辑很简单,获取该目录下所有文件的信息,对每一个文件,打开文件、循环读取数据、写入目标位置,然后关闭文件,最后关闭输出文件。这里粗体打印的几个函数上面都有介绍,不再赘述。
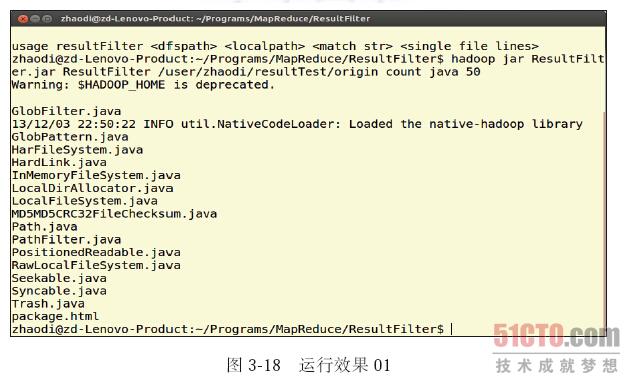
我们在自己机器上预装的hadoop-1.0.4 上简单试验了这个程序,在hadoop 源码中拷贝了几个文件,然后上传到HDFS 中,文件如下(见图3-17):
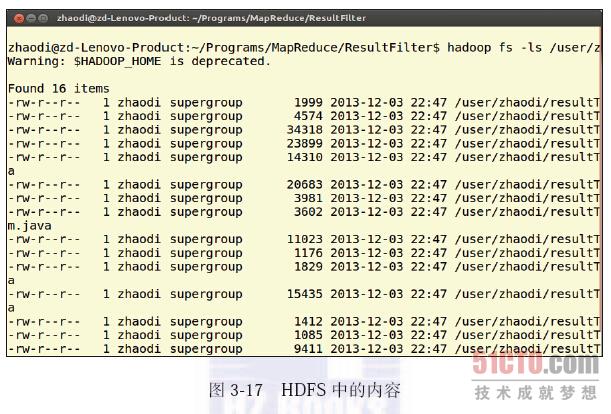
然后,编译运行一下该示例程序,显示一下目标文件内容,结果如图3-18 所示,其中,将出现“java”字符串的每一行都输出到文件中。