
比如经济上,黄仁宇先生对宋朝经济的分析中发现了“数目字管理”(即定量分析)的广泛应用(可惜王安石变法有始无终)。又如军事,“向林彪学习数据挖掘”的桥段不论真假,其背后量化分析的思想无疑有其现实基础,而这一基础甚至可以回推到2000多年前,孙膑正是通过编造“十万灶减到五万灶再减到三万灶”的数据、利用庞涓的量化分析习惯对其进行诱杀。
到上世纪50-60年代,磁带取代穿孔卡片机,启动了数据存储的革命。磁盘驱动器随即发明,它带来的最大想象空间并不是容量,而是随机读写的能力,这一下子解放了数据工作者的思维模式,开始数据的非线性表达和管理。数据库应运而生,从层次型数据库(IBM为阿波罗登月设计的层次型数据库迄今仍在建行使用),到网状数据库,再到现在通用的关系数据库。与数据管理同时发源的是决策支持系统(DSS),80年代演变到商业智能(BI)和数据仓库,开辟了数据分析——也就是为数据赋予意义——的道路。

那个时代运用数据管理和分析最厉害的是商业。第一个数据仓库是为宝洁做的,第一个太字节的数据仓库是在沃尔玛。沃尔玛的典型应用是两个:一是基于retaillink的供应链优化,把数据与供应商共享,指导它们的产品设计、生产、定价、配送、营销等整个流程,同时供应商可以优化库存、及时补货;二是购物篮分析,也就是常说的啤酒加尿布。关于啤酒加尿布,几乎所有的营销书都言之凿凿,我告诉大家,是Teradata的一个经理编的,人类历史上从没有发生过,但是,先教育市场,再收获市场,它是有功的。
仅次于沃尔玛的乐购(Tesco),强在客户关系管理(CRM),细分客户群,分析其行为和意图,做精准营销。
这些都发生在90年代。00年代时,科研产生了大量的数据,如天文观测、粒子碰撞,数据库大拿吉姆·格雷等提出了第四范式,是数据方法论的一次提升。前三个范式是实验(伽利略从斜塔往下扔),理论(牛顿被苹果砸出灵感,形成经典物理学定律),模拟(粒子加速太贵,核试验太脏,于是乎用计算代替)。第四范式是数据探索。这其实也不是新鲜的,开普勒根据前人对行星位置的观测数据拟合出椭圆轨道,就是数据方法。但是到90年代的时候,科研数据实在太多了,数据探索成为显学。在现今的学科里,有一对孪生兄弟,计算XX学和XX信息学,前者是模拟/计算范式,后者是数据范式,如计算生物学和生物信息学。有时候计算XX学包含了数据范式,如计算社会学、计算广告学。
2008年克里斯·安德森(长尾理论的作者)在《连线》杂志写了一篇《理论的终结》,引起轩然大波。他主要的观点是有了数据,就不要模型了,或者很难获得具有可解释性的模型,那么模型所代表的理论也没有意义了。跟大家说一下数据、模型和理论。大家先看个粗糙的图。
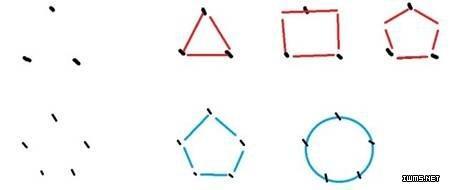
首先,我们在观察客观世界中采集了三个点的数据,根据这些数据,可以对客观世界有个理论假设,用一个简化的模型来表示,比如说三角形。可以有更多的模型,如四边形,五边形。随着观察的深入,又采集了两个点,这时发现三角形、四边形的模型都是错的,于是确定模型为五边形,这个模型反映的世界就在那个五边形里,殊不知真正的时间是圆形。
大数据时代的问题是数据是如此的多、杂,已经无法用简单、可解释的模型来表达,这样,数据本身成了模型,严格地说,数据及应用数学(尤其是统计学)取代了理论。安德森用谷歌翻译的例子,统一的统计学模型取代了各种语言的理论/模型(如语法),能从英文翻译到法文,就能从瑞典文翻译到中文,只要有语料数据。谷歌甚至能翻译克莱贡语(StarTrek里编出来的语言)。安德森提出了要相关性不要因果性的问题,以后舍恩伯格(下面称之为老舍)只是拾人牙慧了。
当然,科学界不认同《理论的终结》,认为科学家的直觉、因果性、可解释性仍是人类获得突破的重要因素。有了数据,机器可以发现当前知识疆域里面隐藏的未知部分。而没有模型,知识疆域的上限就是机器线性增长的计算力,它不能扩展到新的空间。在人类历史上,每一次知识疆域的跨越式拓展都是由天才和他们的理论率先吹起的号角。
2010年左右,大数据的浪潮卷起,这些争论迅速被淹没了。看谷歌趋势,”bigdata”这个词就是那个时间一下子蹿升了起来。吹鼓手有几家,一家是IDC,每年给EMC做digitaluniverse的报告,上升到泽字节范畴(给大家个概念,现在硬盘是太字节,1000太=1拍,阿里、Facebook的数据是几百拍字节,1000拍=1艾,百度是个位数艾字节,谷歌是两位数艾字节,1000艾=1泽);一家是麦肯锡,发布《大数据:创新、竞争和生产力的下一个前沿》;一家是《经济学人》,其中的重要写手是跟老舍同著《大数据时代》的肯尼思?库克耶;还有一家是Gartner,杜撰了3V(大、杂、快),其实这3V在2001年就已经被编出来了,只不过在大数据语境里有了全新的诠释。
咱们国内,欢总、国栋总也是在2011年左右开始呼吁对大数据的重视。
2012年子沛的书《大数据》教育政府官员有功。老舍和库克耶的《大数据时代》提出了三大思维,现在已经被奉为圭臬,但千万别当作放之四海而皆准的真理了。
比如要数据全集不要采样。现实地讲,1.没有全集数据,数据都在孤岛里;2.全集太贵,鉴于大数据信息密度低,是贫矿,投入产出比不见得好;3.宏观分析中采样还是有用的,盖洛普用5000个样本胜过几百万调查的做法还是有实践意义;4.采样要有随机性、代表性,采访火车上的民工得出都买到票的结论不是好采样,现在只做固定电话采样调查也不行了(移动电话是大头),在国外基于Twitter采样也发现不完全具有代表性(老年人没被包括);5.采样的缺点是有百分之几的偏差,更会丢失黑天鹅的信号,因此在全集数据存在且可分析的前提下,全量是首选。全量>好的采样>不均匀的大量。
再说混杂性由于精确性。拥抱混杂性(这样一种客观现象)的态度是不错的,但不等于喜欢混杂性。数据清洗比以前更重要,数据失去辨识度、失去有效性,就该扔了。老舍引用谷歌PeterNovig的结论,少数高质量数据+复杂算法被大量低质量数据+简单算法打败,来证明这一思维。Peter的研究是Web文本分析,确实成立。但谷歌的深度学习已经证明这个不完全对,对于信息维度丰富的语音、图片数据,需要大量数据+复杂模型。
最后是要相关性不要因果性。对于大批量的小决策,相关性是有用的,如亚马逊的个性化推荐;而对于小批量的大决策,因果性依然重要。就如中药,只到达了相关性这一步,但它没有可解释性,无法得出是有些树皮和虫壳的因导致治愈的果。西药在发现相关性后,要做随机对照试验,把所有可能导致“治愈的果”的干扰因素排除,获得因果性和可解释性。在商业决策上也是一样,相关性只是开始,它取代了拍脑袋、直觉获得的假设,而后面验证因果性的过程仍然重要。
把大数据的一些分析结果落实在相关性上也是伦理的需要,动机不代表行为。预测性分析也一样,不然警察会预测人犯罪,保险公司会预测人生病,社会很麻烦。大数据算法极大影响了我们的生活,有时候会觉得挺悲哀的,是算法觉得了你贷不贷得到款,谷歌每调整一次算法,很多在线商业就会受到影响,因为被排到后面去了。
下面时间不多了,关于价值维度,我贴一些以前讲过的东西。大数据思想中很重要的一点是决策智能化之外,还有数据本身的价值化。这一点不赘述了,引用马云的话吧,“信息的出发点是我认为我比别人聪明,数据的出发点是认为别人比我聪明;信息是你拿到数据编辑以后给别人,而数据是你搜集数据以后交给比你更聪明的人去处理。”大数据能做什么?价值这个V怎么映射到其他3V和时空象限中?我画了个图:
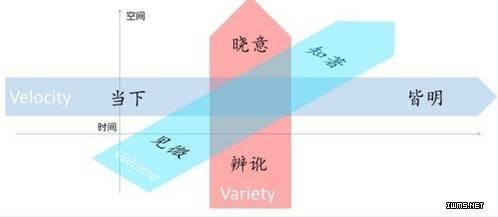
再贴上解释。“见微”与“知著”在Volume的空间维度。小数据见微,作个人刻画,我曾用《一代宗师》中“见自己”形容之;大数据知著,反映自然和群体的特征和趋势,我以“见天地、见众生”比喻之。“著”推动“微”(如把人群细分为buckets),又拉动“微”(如推荐相似人群的偏好给个人)。“微”与“著”又反映了时间维度,数据刚产生时个人价值最大,随着时间decay最后退化为以集合价值为主。
“当下”和“皆明”在Velocity的时间维度。当下在时间原点,是闪念之间的实时智慧,结合过往(负轴)、预测未来(正轴),可以皆明,即获得perpetual智慧。《西游记》里形容真假孙悟空,一个是“知天时、通变化”,一个是“知前后、万物皆明”,正好对应。为达到皆明,需要全量分析、预测分析和处方式分析(prescriptiveanalytics,为让设定的未来发生,需要采取什么样的行动)。
“辨讹”和“晓意”在Variety的空间维度。基于大体量、多源异质的数据,辨讹过滤噪声、查漏补缺、去伪存真。晓意达到更高境界,从非结构数据中提取语义、使机器能够窥探人的思想境界、达到过去结构化数据分析不能达到之高度。
先看知著,对宏观现象规律的研究早已有之,大数据的知著有两个新特点,一是从采样到全量,比如央视去年“你幸福吗”的调查,是街头的采样,前不久《中国经济生活大调查》关于幸福城市排名的结论,是基于10万份问卷(17个问题)的采样,而清华行为与大数据实验室做的幸福指数(继挺兄、我、还有多位本群群友参与),是基于新浪微博数据的全集(托老王的福),这些数据是人们的自然表达(而不是面对问卷时的被动应对),同时又有上下文语境,因此更真实、也更有解释性。北上广不幸福,是因为空气还是房价或教育,在微博上更容易传播的积极情绪还是消极情绪,数据告诉你答案。《中国经济生活大调查》说“再小的声音我们都听得见”,是过头话,采样和传统的统计分析方法对数据分布采用一些简化的模型,这些模型把异常和长尾忽略了,全量的分析可以看到黑天鹅的身影,听到长尾的声音。
另一个特点是从定性到定量。计算社会学就是把定量分析应用到社会学,已经有一批数学家、物理学家成了经济学家、宽客,现在他们也可以选择成为社会学家。国泰君安3I指数也是一个例子,它通过几十万用户的数据,主要是反映投资活跃程度和投资收益水平的指标,建立一个量化模型来推知整体投资景气度。
再看见微,我认为大数据的真正差异化优势在微观。自然科学是先宏观、具体,进入到微观和抽象,这时大数据就很重要了。我们更关注社会科学,那是先微观、具体,再宏观、抽象,许小年索性认为宏观经济学是伪科学。如果市场是个体行为的总和,我们原来看到是一张抽象派的画,看不懂,通过客户细分慢慢可以形成一张大致看得懂的现实图景,不过是马赛克的,再通过微分、甚至定位个人,形成高清图。我们每一个人现在都生活在零售商的bucket中(前面说的乐购创造了这个概念),最简单的是高收入、低收入这类反映背景的,再有就是反映行为和生活方式的,如“精打细算”、“右键点击一族”(使用右键的比较techsavvy)。反过来我们消费者也希望能够获得个性化的尊崇,Nobodywantstobenobodytoday。
了解并掌握客户比以往任何时候都更重要。奥巴马赢在大数据上,就是因为他知道西岸40-49岁女性的男神是乔治·克鲁尼,东岸同样年龄段女性的偶像则是莎拉·杰西卡·帕克(《欲望都市》的主角),他还要更细分,摇摆州每一个郡每一个年龄段每一个时间段在看什么电视,摇摆州(俄亥俄)1%选民随时间变化的投票倾向,摇摆选民在Reddit上还是Facebook上,都在其掌握之中。
对于企业来说,要从以产品为中心,转到以客户(买单者)甚至用户(使用者)为中心,从关注用户背景到关注其行为、意图和意向,从关注交易形成转到关注每一个交互点/触点,用户是从什么路径发现我的产品的,决定之前又做了什么,买了以后又有什么反馈,是通过网页、还是QQ、微博或是微信。
再讲第三个,当下。时间是金钱,股票交易就是快鱼吃慢鱼,用免费股票交易软件有几秒的延迟,而占美国交易量60-70%的高频程序化交易则要发现毫秒级、低至1美分的交易机会。时间又是生命,美国国家大气与海洋管理局的超级计算机在日本311地震后9分钟发出海啸预警,已经太晚。时间还是机会。现在所谓的购物篮分析用的其实并不是真正的购物篮,而是结帐完的小票,真正有价值的是当顾客还拎着购物篮,在浏览、试用、选择商品的时候,在每一个触点影响他/她的选择。数据价值具有半衰期,最新鲜的时候个性化价值最大,渐渐退化到只有集合价值。当下的智慧是从刻舟求剑到见时知几,原来10年一次的人口普查就是刻舟求剑,而现在东莞一出事百度迁徙图就反映出来了。当然,当下并不一定是完全准确的,其实如果没有更多、更久的数据,匆忙对百度迁徙图解读是可能陷入误区的。
第四个,皆明。时间有限,就简单说了。就是从放马后炮到料事如神(predictiveanalytics),从料事如神到运筹帷幄(prescriptiveanalytics),只知道有东风是预测分析,确定要借箭的目标、并给出处方利用草船来借,就是处方性分析。我们现在要提高响应度、降低流失率、吸引新客户,需要处方性分析。
辨讹就是利用多源数据过滤噪声、查漏补缺和去伪存真。20多个省市的GDP之和超过全国的GDP就是一个例子,我们的GPS有几十米的误差,但与地图数据结合就能做到精确,GPS在城市的高楼中没有信号,可以与惯性导航结合。
晓意涉及到大数据下的机器智能,是个大问题,也不展开了。贴一段我的文章:有人说在涉及“晓意”的领域人是无法替代的。这在前大数据时代是事实。《点球成金(Moneyball)》讲的是数量化分析和预测对棒球运动的贡献,它在大数据背景下出现了传播的误区:一、它其实不是大数据,而是早已存在的数据思维和方法;二、它刻意或无意忽略了球探的作用。从读者看来,奥克兰竞技队的总经理比利·比恩用数量化分析取代了球探。而事实是,在运用数量化工具的同时,比恩也增加了球探的费用,军功章里有机器的一半,也有人的一半,因为球探对运动员定性指标(如竞争性、抗压力、意志力等)的衡量是少数结构化量化指标无法刻画的。大数据改变了这一切。人的数字足迹的无意识记录,以及机器学习(尤其是深度学习)晓意能力的增强,可能逐渐改变机器的劣势。今年我们看到基于大数据的情感分析、价值观分析和个人刻画,当这些应用于人力资源,已经或多或少体现了球探承担的。


