
Apache Hive是一款以hadoop为基础打造而成的工具,其专长在于利用类SQL语法对大规模非结构化数据集进行分析,从而帮助现有商务智能及企业分析研究人员对Hadoop内容进行访问。作为由Facebook工程师们开发、受到Apache基金会认可并贡献的开源项目,Hive目前已经在商用环境下的大数据分析领域取得了领先地位。
与Hadoop生态系统中的其它组成部分一样,Hive的发展速度同样非常迅猛。在今天的评测文章中,我们将以0.13为目标——该版本解决了其它前续版本中的一些缺陷。0.13版本还显著提升了类SQL查询在多个大规模Hadoop集群之间的处理速度,并针对前续版本中的交互查询机制添加了多项全新功能。 从本质上讲,Hive其实是一套事务型数据存储体系,同时也适用于规模巨大、对查询速度要求不高的相对静态数据集进行分析Hive对现有数据仓库方案作出了很好的补充,但并不属于完整的替代性机制。相反,利用Hive辅助数据仓库能够充分发挥现有投资成果的实际效能,同时又不会对数据容纳能力造成影响。 典型的数据仓库方案包含有众多昂贵的硬件与软件组件,例如RAID或者SAN存储、用于简化及插入数据的优化型ETL(即提取、转换与加载)规程、面向 ERP或者其它后端系统的特定连接机制外加面向地理位置、产品或者销售渠道等企业常见销售事务所设计的规划方案。这类仓库体系通过优化为CPU带来丰富的数据内容,从而为规划方案中预设的各类运营问题找到答案。
相比之下,Hive数据存储机制将大量非结构化数据整合到了一起——其中包括日志文件、客户推文、电子邮件信息、地理数据以及CRM交互等——并将它们以非结构化格式保存在成本低廉的商用硬件之上。Hive允许分析师们以这些数据为基础构建类似于数据库的项目结构,引入与传统表、列以及行相仿的机制并针对其编写类SQL查询。这意味着用户完全可以根据查询特性在同一套数据集之上采用不同类型的处理规划,从而透过收集到的数据找出关键性运营问题的确切答案。
过去,Hive查询一直存在比较严重的延迟状况,即使是涉及数据量不大的小型查询也需要耗费相当长的一段时间——这是因为查询需要首先被转化为映射 -归约作业,而后才能提交给集群并以批量方式得到执行。这种延迟一般不至于造成什么问题,因为早在查询规划与映射-归约机制起效之前、查询本身就会对整个处理周期的时耗作出预判——至少在运行Hive设计思路所指向的大规模数据集时是如此。
不过用户们很快发现,这类运行周期过长的查询流程在多用户环境下会造成严重的不便甚至麻烦,因为在这种状况下单一作业有可能成为整体集群的首要完成目标。 为了解决这一难题,Hive社区组织起新一轮努力(也被称为‘毒刺’项目)以改善查询处理速度,其目标是让Hive有能力适应实时、交互式查询与探索性操作的需求。这部分改进成效在Hive 0.11、0.12以及0.13三个版本中开始陆续出现。
最后,尽管HiveQL查询语言以SQL-92为基础,但它仍然与SQL之间存在一系列重大差别——原因很简单,前者运行在Hadoop基础之上。举例来说,DDL(即数据定义语言)命令需要考虑到表中现有多用户文件系统能够支持多种存储格式这一客观现实。不过总体而言,SQL用户在使用 HiveQL语言时能够获得理想的熟悉之感,而且在适应过程中应该不会遇到任何障碍。 Hive平台架构 从上到下,Hive的平台架构看起来与任何其它关系型数据库并没有什么不同。用户编写SQL查询并将其提交至处理流程,且可以使用与数据库引擎直接交互的命令行工具或者通过JDBC或ODBC与数据库进行通信的第三方工具。Hive的具体架构如下图所示:
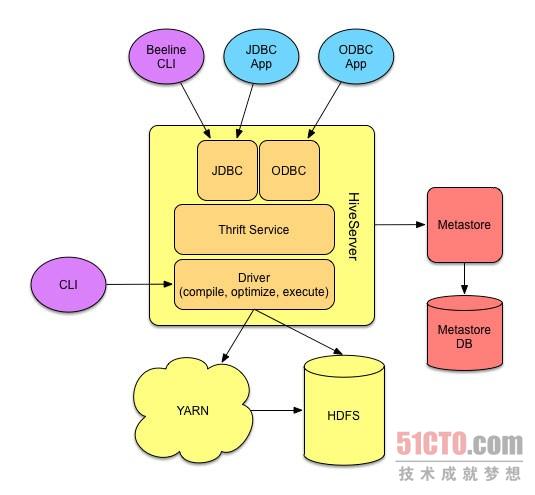
Hive平台架构示意图。
通过Mac及Windows系统下的JDBC以及ODBC驱动程序,数据工作人员们可以将自己喜爱的SQL客户端与Hive相对接,从而对表进行浏览、查询以及创建。对于资深用户而言,Hive也提供原始的胖客户端CLI、能够与Hive驱动程序直接交互。这套客户端最为强大且要求与Hadoop直接对接,因此特别适合处理本地网络执行事务——防火墙、DNS以及网络拓朴结构都将不是问题。
Hive元存储机制HCatalog原本曾经作为独立的Hadoop项目存在,如今则成为Hive发行版当中的组成部分。在其自有关系型数据库的支持之下,HCatalog能够免去在Hive当中定义规划的步骤、简化新查询同时使此类规划能够为Hadoop工具链中的其它工具——例如Pig——所用。


